ServiceDesk 4.8.179 Update 08/23/20
Structural Improvements, Upgraded Hand-Holding Guidance and New Tools for GraphHopper-based Whole-Roster Optimizations: Introduction
As we've continued to work with initial users of this system, we've learned more and more how even a few imperfections in setup of the problem (the "problem" is the whole roster of needs as presented to GraphHopper) can easily result in a "solution" that is anything but.
We're not referring here to imperfections in how ServiceDesk assembles "the problem" for presentation of for GraphHopper (though indeed there have been imperfections in that that we've discovered and fixed along the way); rather, we're referring to imperfections in a how a user's jobs, appointments and technicians are setup, vis-a-vis the problem -- in a manner that, essentially, makes any programmatic solution of the problem logically incoherent.
As an example, if you indicate that a particular appointment requires a particular skill set, and yet you have it Definite-assigned to a technician that you have not indicated as having such required skills, GraphHopper faces a quandary. On the one hand, it knows it must put this job into that tech's route. On the other hand, it knows it cannot put it into that tech's route. What's it to do? Answer; it refuses to route the job at all, and reports back accordingly.
In fact, from its first iteration of this optimization feature, ServiceDesk has relayed to the user (in a simple dialog after the response comes back from GraphHopper) information about any submitted item that (for any of various reasons) GraphHopper found it impossible include in its optimized solution. Regardless, users paid scant attention. Worse still, they felt the system had failed when seeing one or more techs with obviously cockeyed routes. What they did not realize was that ServiceDesk had rearranged for such portion of the roster as had been optimized, and this result was now combined with items that had not been optimized.
If you understand what was just described, you can likely realize why an "ugly" result might reasonably be expected.
Regardless, prior to the last announced release (see here), we'd done little to help users understand this, or to help protect them against it, or to help them advance past it.
The truth is, we had to ourselves learn about such potential pitfalls, as we went along.
At any rate, we've now made some great advances.
By way of analogy, when we first rolled out the system we had it working perfectly in a clean and sterile lab. It's taken time and experience to learn about the challenges of a dirty real world, and to make such adaptations as are needed to enable it to work there, as well.
Structural Improvements
Item one:
The above-described example (of a situation GraphHopper can't coherently handle) is but one example among a few different such situations that might potentially arise. It occurred to us that, for some of these, we could build logic into ServiceDesk whereby it spots such logical impossibilities and informs you, before even submitting to GraphHopper.
So, that is now built into the system.
As ServiceDesk works to assemble a "problem" for presentation to GraphHopper, it will spot either of two kinds of logical impossibility. If present, it will inform accordingly, and refuse to proceed, until after you've corrected the situation:
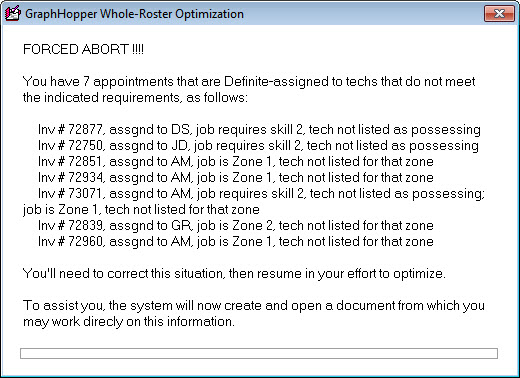
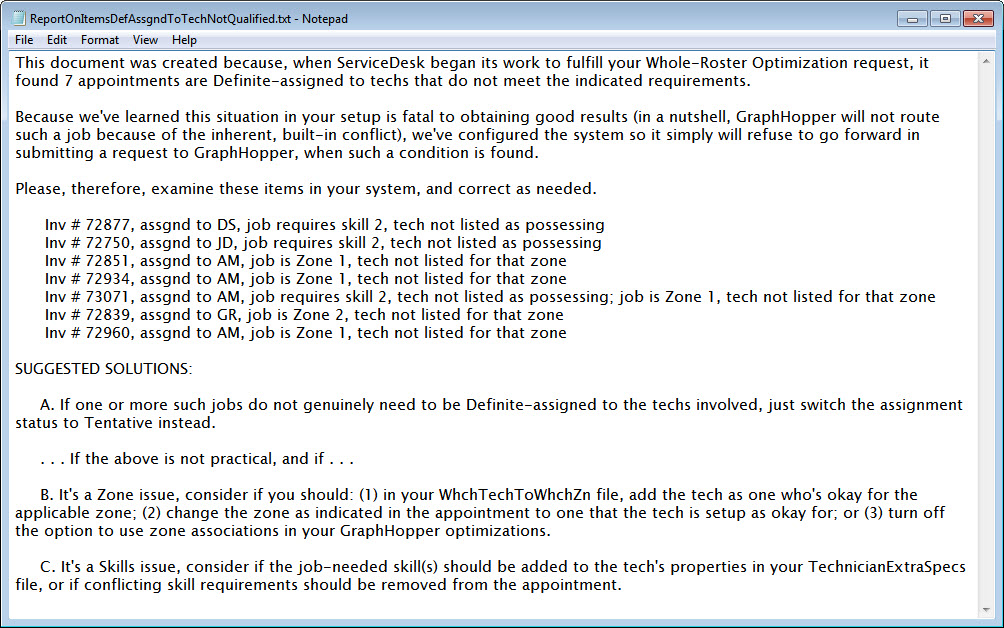
When the indicated document opens, you'll find it's nicely configured to aid you in correcting the cited situations:
You can likely see how much better it is for the system to detect such situations in advance, and demand correction, before submitting to GraphHopper.
Item two:
Formerly, when ServiceDesk submitted a problem for solution and got a result back from GraphHopper, it would immediately (and without preamble) re-arrange appointments in your roster to fit GraphHopper's work (regardless of whether GraphHopper had in fact managed to include all of such appointments as were submitted to it). Based on the last prior-announced improvements (see here), ServiceDesk would then inform you if (and by what reason) you should expect the result to be less than satisfactory.
In retrospect, we realize that was foolish.
We've now reversed the sequence.
Now, ServiceDesk will begin, after getting its response back from GraphHopper, by telling you of any items GraphHopper could not include in its routing (and also remind of any items that could not be submitted initially, though these were already disclosed in preamble dialog before your final approval to submit), giving you an evaluation of quality overall, and asking if you wish to proceed in having ServiceDesk re-arrange your roster to fit such portion of it as GraphHopper has in fact optimized. It now only so proceeds with your consent at such point.
In fact, the series of dialogs (different depending on quality of result) are similar to those shown in the last release (see here) except they're now changed to fit a pre-insertion-of-GraphHopper-result context, rather than post-insertion. Likewise, the detailed document that is opened for you is similarly changed, now with special emphasis on seeking to help you fix any issues -- as prelude before running the optimization again and with any problems fixed -- so that, ultimately, a truly great optimization can be achieved, and then inserted into your roster.
Upgraded Hand-Holding
In a way, the above-discussed structural improvements are part of the upgraded hand-holding. But there some other elements, too.
For example, the document that reports to you on the result from GraphHopper's work formerly just passed through, to you, the same such verbiage as is provided by GraphHopper to indicate why if could not include particular jobs in its optimized solution. That verbiage was often opaque. In other words, for a regular human being, it was pretty tough to understand what it meant. Now, we've coded so that this report will in many instances replace GraphHopper's verbiage with words that will more readily provide you with a sensible meaning.
Similarly, that same document now includes a section that describes several techniques you might use to easily see within ServiceDesk details regarding the matters that prevented items from inclusion in the optimization, and of how to address those before you initiate a new optimization request.
Finally, the system is now quite overt in directing you away from inserting an optimization solution that is so partial that it's likely to do more harm than good (and refusing to offer incorporation in the worst cases). It is now likewise overt in guiding away from insertion of time frames when circumstances are not likely ideal for that action.
Under this improved hand-holding, by the way, all the dialog and document images as shown in the last-prior WorkDiary announcement (see here) are replaced with ones that, though they look similar, now fit the new structure instead of the old. When we get around to it, we'll go back and replace those images with new.
New Tools
As we at Rossware have worked with clients seeking to understand why, in a number of cases, optimization requests did not produce happy results, we've found ourselves needing to hunt down and investigate individual items to see why they don't fit a good result. As we've done this repeatedly, we've found we could ourselves benefit from some upgraded tools. Naturally, we realized you could likewise benefit.
The first such tool is embodied in the fact ServiceDesk now pre-screens for a few logical impossibilities, before even sending to GraphHopper (see here). If any are found, it of course aborts and informs you of details.
Regardless, even where those details are nicely pointed out, it can be some work to go find the items in your DispatchMap, verify the alleged details, and then work to fix them. Especially, it can be some work if you don't have tools to make it easy.
We earlier added a tool that makes it easy to see parameters as applicable to a tech (see here), and we've added more parameters to that same showing since.
Regardless, if you're looking in your DispatchMap and have scores of technicians and hundreds of jobs on just a single day's roster, it may not be easy to instantly isolate a particular tech and his route.
To be sure, we've long had a feature called "Show for One Tech." Just right-click on a tech's name at the top of his list in the DispatchMap. ServiceDesk then hides lists and route lines for all other techs. This makes that particular tech's roster and route really stand out.
It's a great feature, but we at Rossware had forgotten that we'd made another way to trigger it. We kept finding ourselves, working in a client's data and needing to isolate a tech, yet not knowing where to find that tech among scores of techs in the list area of the DispatchMap. Sometimes it took a minute of perusing before finding the tech of interest. We resolved to make an easier "locate" tool. It turns out, however, it's already there, based on the alternate trigger (of which we'd forgotten) for the "Show for One Tech" feature. That alternate trigger is hit "T" on your keyboard (the "T" is for "T"echs), then (as prompted) type in the initials of interest. You'll immediately see your DispatchMap displayed in "Show for One Tech"mode, and as applicable to the tech whose initials you've provided.
Okay, it turns out that's not exactly a new feature (since it already existed), but it's highly useful to the purposes described here.
There are several other long-existing tools that are useful for this context, and, for your convenience, most of these are are now listed in the post-optimization report that's opened for you as a document in all cases where the optimization solution was less than complete.
There is also a completely new tool/operative-function (call it a "trick" if you like) that's added with this release.
First, we'll explain why this new "trick" is important.
Working with a couple of clients on instances where, post-optimization, one or more appointments appeared to be awfully placed in terms of tech-assigned, other jobs for that tech and sequence, we searched and hunted, searched and hunted . . . and searched and hunted . . . seeking to determine why GraphHopper either refused to route a particular job at all, or, if it did route, included it in a route and sequence that, at least on basis of what we could see in the DispatchMap, made absolutely no sense.
Guess what we found?
Simply, in several instances we found that the grid-coordinates on an appointment (which determine display position in the DispatchMap) dictated a different geographic location than the underlying JobRecord's Lat/Lon geocoding (which of course is what GraphHopper is going by).
In some instances it was one that was erroneous. In some instances it was the other. In some instances it was both.
It doesn't take a rocket scientist to understand how this could make a displayed route in the DispatchMap look very whacked.
But how easy is it to investigate, where you find no other explanation for GraphHopper either refusing to route a job or seeming to route it badly, to see if this is the underlying reason?
Until now, it was not particularly easy.
Now it's a piece of cake.
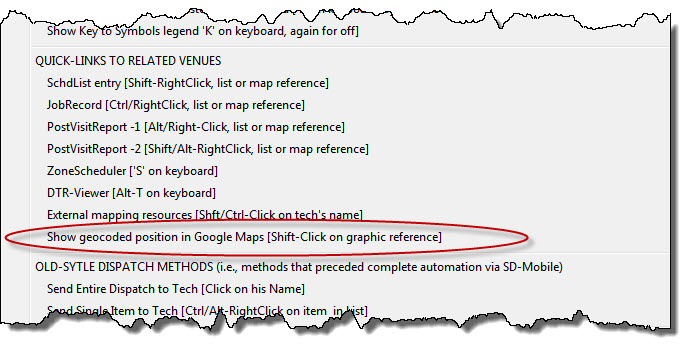
Our new tool is called "Show Geocoded Position." To use it, do a Shift-Click on any graphic appointment reference. ServiceDesk will immediately open a Window in Google Maps, showing that Lat/Lon location as pulled from ExtraNotes in the underlying JobRecord. You can quickly zoom out, and see if the geographic position as shown there at least approximates the same as shown in your DispatchMap. If the two do not agree, you've found the explanation, and may then work for fix it.
Like most other tricks, by the way, guidance to this one has likewise been added into the DispatchMap Cheat-Sheet: